



Social Media
Follow us on our social media channels


Contact Us
Thank you! We will get back to you as soon as possible.
Oops! Something went wrong while submitting the form.

Trusted AI does not begin with the model. It begins with the quality of the knowledge foundation underneath it.
In production, trust is not won through a clever prompt or the latest agent framework. It depends on whether the AI is grounded enough in the enterprise domain to understand what things are, contextualized enough to understand how they relate, and structured enough to explain why it arrived at an answer.
That is the core problem I spend most of my time working on. In large-scale AI initiatives, the challenge is not getting a system to look good in a demo. It is getting it to behave reliably under ambiguity, at scale, with changing data, and under real operational pressure.
I have been using the Menome Knowledge Vault and an art collection curation project for a local gallery as a practical way to illustrate these ideas. It is a small, tangible example, but the principles are the same ones that underpin trusted AI at enterprise scale.
Enterprise AI faces a brutal equation. It can take hundreds of correct answers to build user confidence, but a single wrong answer, especially in a high-stakes context, can permanently erode adoption. That is not primarily a model quality problem. It is an architecture problem.
When AI systems fail in production, the causes are usually familiar: fragmented or low-quality data, insufficient domain context, ambiguous queries with no structure to resolve them, and agents that lose state across reasoning steps.
In small-scale demos, these issues often remain hidden. The scope is narrow, the data is curated, and there is usually enough human oversight to smooth over the gaps. At that scale, the weaknesses may not surface, or they may simply not matter enough to be noticed.
As scale, scope, and complexity increase, those weaknesses become harder to ignore. Retrieval becomes less precise. Answers become less consistent. Reasoning quality degrades. Costs rise. And eventually the system starts producing responses that sound credible, but cannot be trusted.
A common example is the typical vector-search AI demo. Take a collection of PDFs or documents from Google Drive, chunk them into smaller passages, generate embeddings, store them in a vector database, and connect the result to a chat interface. Very quickly, you have a system that can answer questions about the documents. For a proof of concept, this can be impressive.
At a small scale, vector stores can work quite well. But at a larger scale, two problems begin to surface.
The first is loss of context. Chunking a document for vector retrieval is a bit like tearing it into many small pieces and then grouping those pieces by semantic similarity. When a question comes in, the system searches for pieces that look similar to the query and uses them to assemble an answer.

That works reasonably well when the document set is small and homogeneous. But as more documents are added, the fidelity of those similarity groupings starts to break down. The retrieved chunks may be topically related to the question, but less connected to the actual meaning the user needs. Similarity is not the same as relevance.
The second problem is that document structure matters. Many enterprise documents derive meaning not just from the words they contain, but from how those words are organized. Contracts, environmental assessments, regulations, audit reports, and technical manuals all depend on structure for interpretation.
A clause in a contract means something different depending on the section it appears in, what it references, and what conditions surround it. Once that document is chopped into isolated chunks and grouped only by similarity, much of that structural meaning is discarded.
This is where vector-only approaches begin to struggle. They may retrieve text that is semantically similar, but contextually wrong. The answer can still sound fluent, because the language model fills in the gaps. But fluency is not the same as fidelity.
If the retrieved chunks are no longer anchored to the structure they came from, the system can generate responses that appear plausible while no longer being traceable to anything solid.
That is why lexical structure needs to be preserved, not discarded. Document hierarchy, section relationships, references, and proximity all carry meaning. Graph modeling provides a way to retain that meaning by representing the structure of the document itself and the relationships within it.
Instead of treating text as disconnected fragments, it allows the system to reason over how those fragments fit into a larger whole.
That distinction matters. A vector store can help find similar language. A graph-based knowledge foundation helps preserve the context that gives that language meaning. In a demo, that difference may be easy to miss. In production, it is often the difference between an answer that is merely plausible and one that is trustworthy.
Language models can compensate by inferring what they should know, but the result is an answer that sounds plausible but cannot be traced back to anything real because the chunks are no longer tied to their structural source.
This issue compounds massively in the enterprise. Not only are there tens of thousands of complex documents stored on network drives, SharePoint, or Google documents, but also a myriad of other databases, SaaS platforms, and systems, all of which contain a part of the overall context needed to answer user questions.
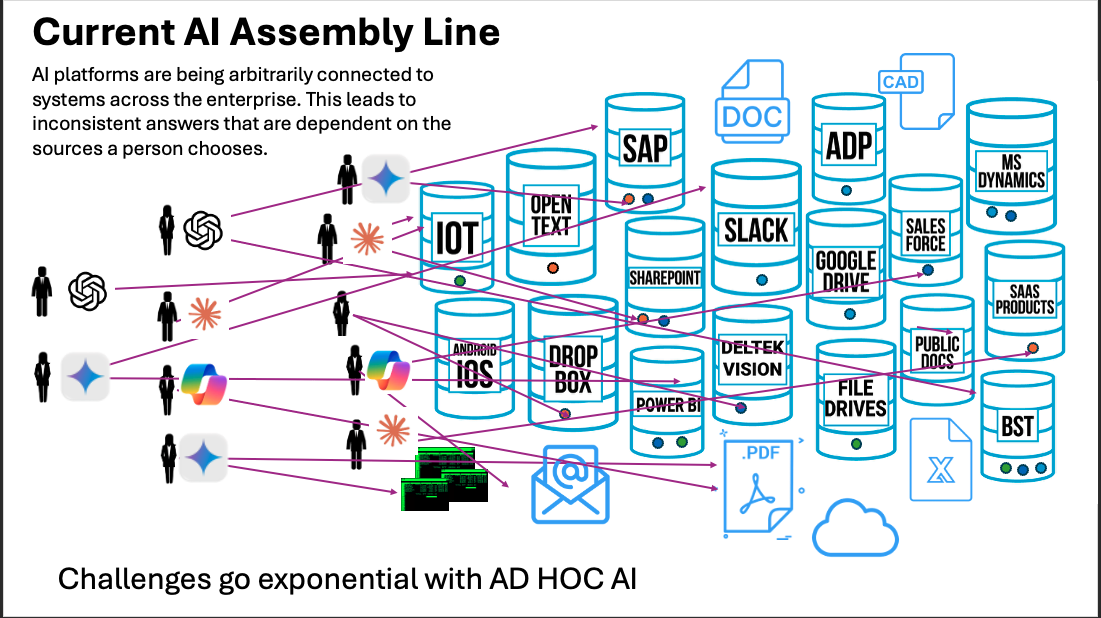
The architecture fix is not a better prompt. It is a better knowledge foundation: a foundation that gives AI models a faithful representation of the domain it is operating in, so that retrieval, reasoning, and memory are all grounded in something coherent rather than assembled from disconnected fragments.

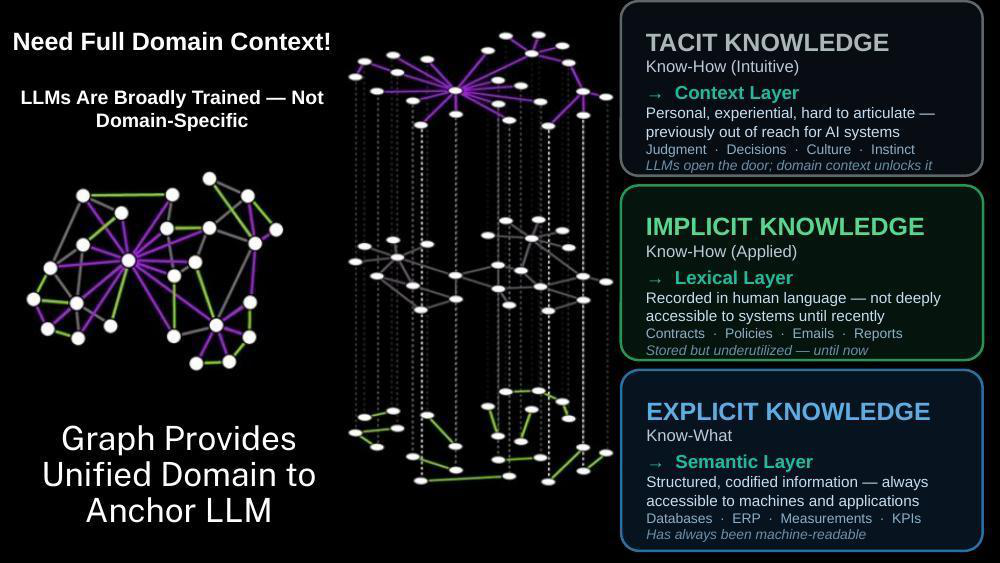
The Knowledge Layer describes the technical foundation that lets AI model a domain well enough to reason inside it reliably. It is a composition of three kinds of knowledge, each mapped to a distinct technical layer.
Explicit knowledge is the know-what of a domain — the structured, codified information that has always been machine-readable. Records, entities, classifications, relationships, measurements. It maps to the semantic layer: a graph foundation that defines how entities connect and what context surrounds them in a way machines can traverse and query. This is the bedrock. Without it, everything else is guesswork.
Implicit knowledge is the know-how captured in language. Documents, reports, correspondence, policies, catalogs, letters — information that is rich and valuable but underused because it lives in prose rather than structure. It maps to the lexical layer, where documents are decomposed into graph-linked nodes, embedded for semantic search, and made accessible through GraphRAG-style retrieval.
The critical distinction: vector search treats documents as disconnected chunks. GraphRAG treats them as a connected knowledge graph where document sections link to the entities they describe. Structure contains context that similarity scores cannot.
Tacit knowledge is the intuitive, experiential understanding that lives in people — the judgment a practitioner brings, the reasoning behind a decision, the institutional memory that evaporates when someone leaves. It maps to the context layer, where conversation history, reasoning traces, and contributed memories are preserved in structured graph form. This is what makes an AI system cumulative rather than amnesiac, which ensures insight is not lost every time a session ends.
When these three layers are connected, the Knowledge Layer becomes more than a store of facts. It becomes a model of the domain. And that distinction is everything.
Facts alone do not create trust. Trust comes from coherent context — the ability to connect an answer to the right entities, the right documents, the right relationships, and, where appropriate, the right lived experience.
Large language models are broadly trained and linguistically capable, but they are not domain-specific. They are strong at language and weak at grounded reality unless the surrounding architecture gives them a reliable map. A graph foundation provides that map: the Knowledge Layer.
Without it, AI systems compensate with heavier prompts, looser retrieval, and more model guesswork. That approach may be enough for a controlled demo. It is rarely enough for production, and when it fails, it fails in exactly the ways the trust equation predicts.
Retrieval surfaces semantically similar but structurally wrong content. Multi-step agents lose state across reasoning turns. Answers start sounding plausible while becoming harder to test, harder to explain, and more expensive to correct.
Graph changes the operating model. Instead of forcing the model to infer everything from loose text, the system can traverse known relationships: this artwork was created by this artist, acquired through this event, referenced in these documents, associated with these people, discussed in these archived notes.
The AI reasons inside a connected representation of the domain. The difference between a system that sounds right and one that is right — and can show you why — lives here.
The Menome Knowledge Vault is a heritage AI initiative built around the art collection at Ranchman's Arts in Calgary — a collection with deep roots in Alberta's ranching history, cultural life, and the people who shaped both.
On the surface, it is a preservation project: digitize the past, make it accessible, inspire future connection. Underneath, it is an applied example of exactly the architecture we have been describing.
Imagine a visitor standing in front of a painting and scanning a QR code. They ask: Who painted this? What is its story? How does this work connect to others in the collection?
A weak implementation might rely on a generic caption and a vector search over detached documents. A stronger implementation starts from the graph. The artwork is connected to the artist, the collection record, the exhibition history, related documents, associated people, and contributed stories. Retrieval is guided by structure, not just similarity.

The semantic layer holds the collection model: artists, artworks, dates, mediums, locations, provenance records, and the relationships between them.
The lexical layer decomposes digitized records. These are derived from curatorial notes, catalog essays, committee minutes, newspaper clippings, correspondence, and links those documents to the entities they describe, making the full heritage of the archive searchable rather than buried.
The context layer preserves the interactions, questions, and stories a member shares about acquiring a piece, the experience a curator recalls from a specific show, and the personal connection an artist describes to a subject.
Over time, the system does not just answer questions about the collection. It becomes a living memory bank shaped by everyone who has engaged with it, from curators, members, historians, and artists.
This is also where the arts setting becomes powerful as a teaching tool. Provenance is explicit knowledge. Curatorial language is implicit knowledge. Personal and cultural memory is tacit knowledge.
Leave any one of those out, and the answer may be fluent, but it will be thinner, less explainable, and less trustworthy. The art context makes this viscerally clear in a way that enterprise data rarely does.
The technical implementation follows the same three-layer pattern at every scale. The semantic layer holds a knowledge asset graph composed of entities, relationships, and schema, which provides structured context for AI queries.
The lexical layer adds GraphRAG capabilities: document decomposition into lexical graph nodes linked to semantic entities, vector search for similarity retrieval, and graph traversal for multi-hop reasoning that pure vector search cannot perform.
The context layer adds agentic memory: short-term conversation context, long-term entity memory built from interactions, and reasoning memory that records how the agent solved past problems so it can improve over time.
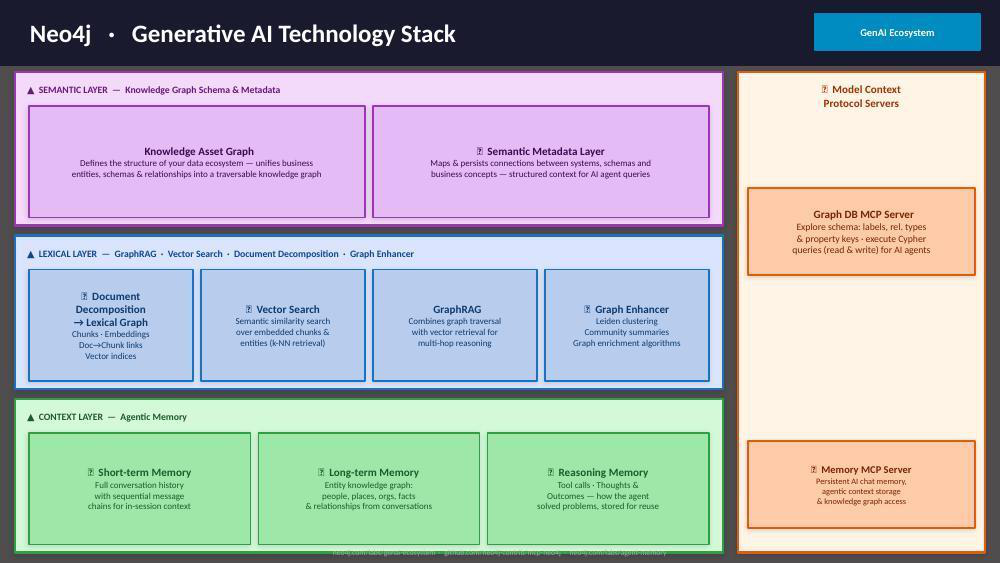
Together, these layers replace the pattern of forcing the model to be magical with the pattern of giving the model a well-structured world to operate in.
The result is AI that can be tested, explained, and trusted not because the model is more capable, but because the architecture gives it less room to go wrong.
The lesson transfers directly. Organizations want AI that operates across messy, distributed, real-world environments and delivers reliable, explainable answers at scale.
The way to get there is not to ask the model to do more. It is to build the knowledge and context foundations that let the model work with a faithful representation of reality.
Build the semantic layer: model your entities, relationships, and domain structure in a graph.
Build the lexical layer: decompose your documents into a knowledge graph linked to the entities they reference, not just indexed for similarity.
Build the context layer: preserve reasoning traces, long-term memory, and contributed knowledge so the system learns from its interactions rather than starting fresh every session.
When those three layers are in place and connected, AI stops reasoning over disconnected fragments and starts reasoning inside a coherent model of the domain.
Answers become more accurate, more explainable, and more defensible. Trust follows naturally: not as a product of better prompts, but as a product of better architecture.
When you model the world well, AI can reason within it.
Whether the domain is cultural heritage, critical infrastructure, software ecosystems, or complex business operations, the principle holds. The Knowledge Vault is an example of a blueprint that scales, from a painting on a wall in Calgary to global AI systems operating at internet scale. The foundation is the same.
Trust is built on a solid foundation of reliable, contextual data. This requires investment, thoughtful design, and time, but trust is worth it. Build it first, and the answers will follow.
Mike Morley is a Senior Solution Engineer at Neo4j and Strategic Advisor to Arcurve AI. With 25+ years in applied AI across environmental, financial, mining, and energy sectors, he helps global organizations design Graph Intelligence foundations for reliable AI in production.
He co-founded Menome Technologies in 2016 — whose work underpins the Knowledge Vault initiative — which was acquired by Arcurve in 2020.
Follow us on our social media channels